Method
Dataset Construction
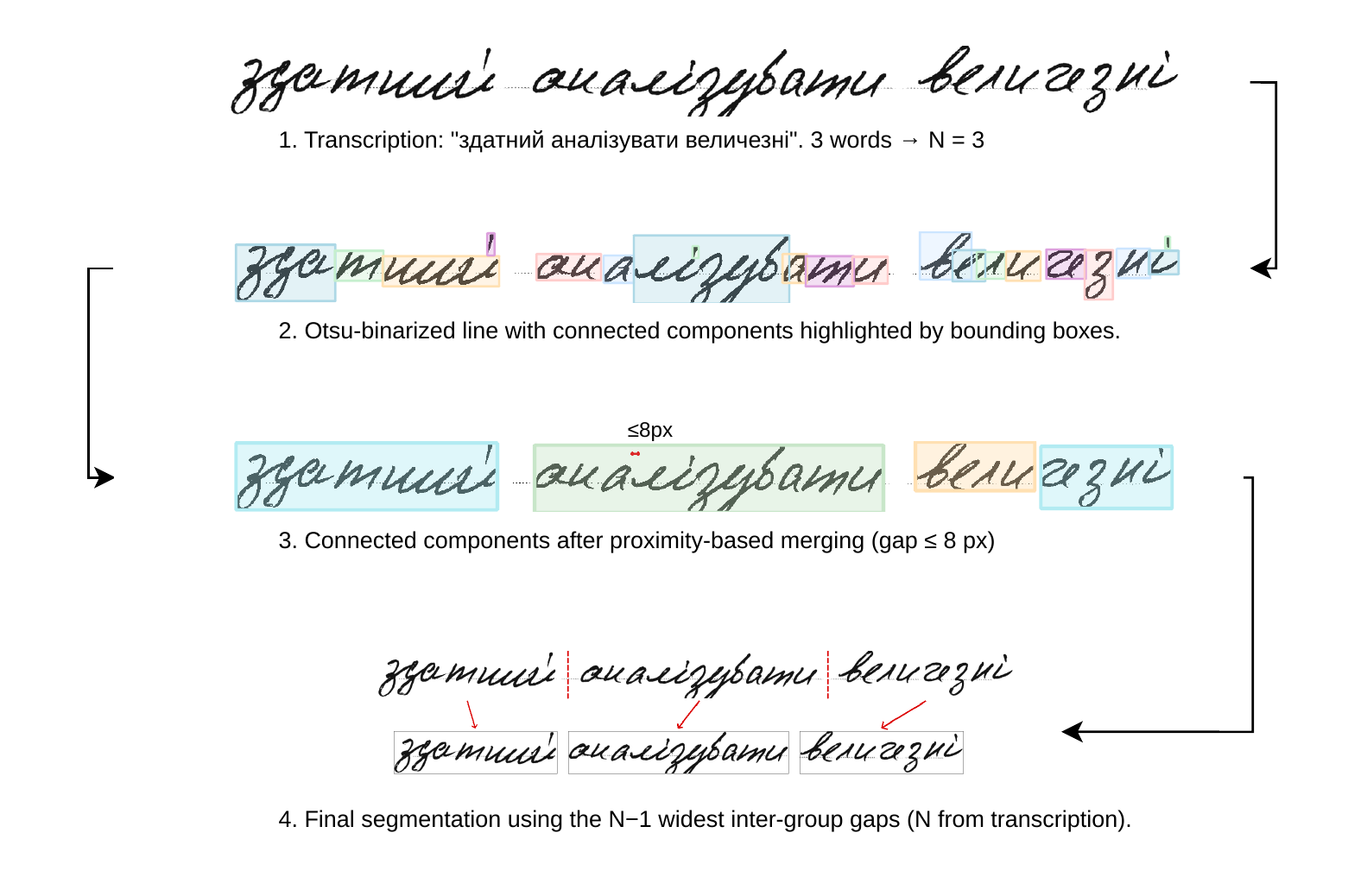
No Ukrainian word-level handwriting dataset with writer labels existed prior to this work. We derive one from the UkrHandwritten line-level corpus[4] (37,111 lines, 331 writers) through a four-stage pipeline: pre-segmentation artifact removal with a NAFNet restoration network, Otsu binarization, connected-component proximity merging (gap ≤ 8 px), and N−1 widest-gap word boundary selection. The method achieves 95.7% boundary accuracy on a 500-line evaluation subset, compared to 71.7% for vertical-projection baselines. After quality filtering and oversampling of rare letters (ф, ї, Щ, Є, Ц, і), the final dataset contains 126,177 word images from 308 writers. The dataset and trained model weights are available via Google Drive links in the GitHub repository.
Model Architecture
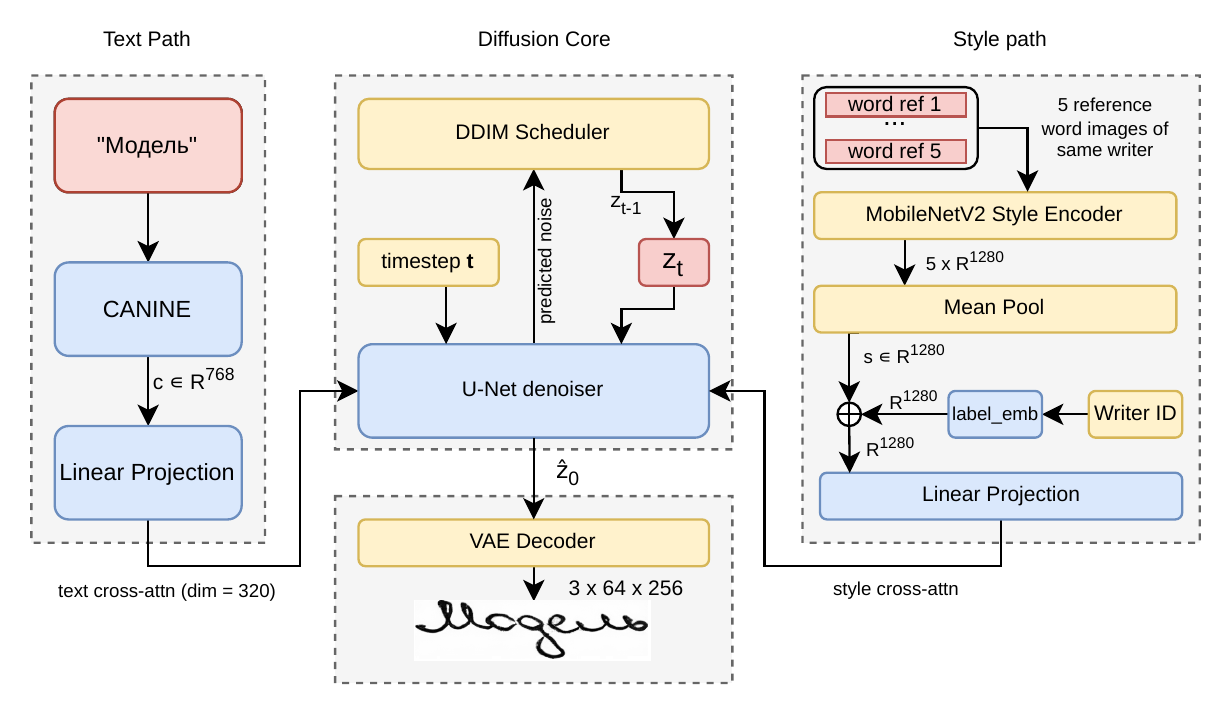
We adopt DiffusionPen[1] without architectural modification. The model is a conditional latent diffusion model operating in the 4×8×32 latent space of a frozen Stable Diffusion v1.5[8] VAE. At each denoising step, a U-Net receives three conditioning signals: (1) a text embedding c ∈ ℝ768 from a CANINE[7] character-level encoder, projected to dimension 320; (2) a style embedding s ∈ ℝ1280 from a frozen MobileNetV2 style encoder trained with triplet loss, mean-pooled over five reference images; and (3) a learned writer label embedding summed with s. Both conditioning signals are injected via cross-attention.
Training & Sentence Assembly
The model is trained for 200 epochs on the 126K dataset with the standard LDM noise-prediction objective on a single RTX 4090 GPU (TF32, batch size 24). Classifier-free guidance uses pdrop = 0.2 for text; style conditioning is never dropped. Inference uses 50 DDIM steps with CFG scale ω = 5.0.
Individual word images are assembled into sentence strips via baseline alignment (span-based body-row detection), brightness normalization, and real handwritten punctuation marks sampled from a bank of 500 training-corpus marks.




